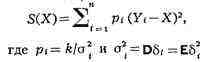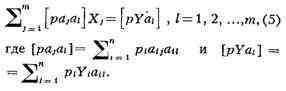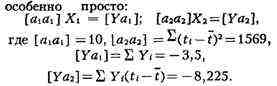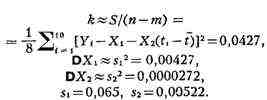![]()
![]()
|
|
|
НАИЛУЧШЕЕ ПРИБЛИЖЕНИЕ, важное понятие теории приближения
функций. Пусть f(x) - произвольная непрерывная функция, заданная на
нек-ром отрезке [а, b], a |f(x)-a1 Полином P*n (х, f), для к-рого уклонение от функции f(x) равно H. п. (такой полином всегда существует), наз. полиномом, наименее уклоняющимся от функции f(x) (на отрезке [а, b]). Понятия H. п. и полинома,
наименее уклоняющегося от функции f(x), были впервые введены П. Л. Чебышевым
(1854) в связи с исследованиями по теории механизмов. Можно также рассматривать
H. п., когда под уклонением функции f(x) от полинома Рп(х)
понимается не максимум выражения (*), а, напр., См. Приближение и интерполирование функций. НАИМЕНЬШЕГО ДЕЙСТВИЯ ПРИНЦИП, один из вариационных принципов механики, согласно к-рому для данного класса сравниваемых друг с другом движений механич. системы действительным является то, для к-рого физ. величина, наз. действием, имеет минимум (точнее, экстремум). Обычно H. д. п. применяется в одной из двух форм. а) H. д. п. в форме
Гамильтона - Остроградского устанавливает, что среди всех кинематически
возможных перемещений системы из одной конфигурации в другую (близкую к
первой), совершаемых за один и тот же промежуток времени, действительным
является то, для к-рого действие по Гамильтону S будет наименьшим. Математич.
выражение H. д. п. имеет в этом случае вид: б) H. д. п. в форме Мопертюи
- JIaгранжа устанавливает, что среди всех кинематически возможных перемещений
системы из одной конфигурации в близкую к ней другую, совершаемых при
сохранении одной и той же величины полной энергии системы, действительным
является то, для к-рого действие по JIaгранжу W будет наименьшим. Математич.
выражение H. д. п. в этом случае имеет вид Лит. см. при ст. Вариационные принципы механики. С. M. Тарг. НАИМЕНЬШЕГО ПРИНУЖДЕНИЯ ПРИНЦИП, то же, что Гаусса принцип. НАИМЕНЬШЕЕ ОБЩЕЕ КРАТНОЕ, двух или нескольких натуральных чисел - наименьшее, делящееся на каждое из них, положительное число. Напр., H. о. к. чисел 2 и 3 есть 6, чисел 6, 8, 9, 15 и 20 есть 360. H. о. к. пользуются при сложении и вычитании дробей: наименьшим общим знаменателем двух или нескольких дробей является H. о. к. их знаменателей. Если известны разложения заданных чисел на простые множители, то для получения H. о. к. этих чисел нужно составить произведение всех множителей, взяв каждый наибольшее число раз, какое он встречается. Так, 6 = 23, 8 = 222, 9 = 33, 15 = 3*5 и 20 = 22*5; поэтому H. о. к. 6, 8, 9, 15 и 20 есть 22233*5 = 360. Понятие H. о. к. применимо не только к числам. Так, напр., H. о. к. двух или нескольких многочленов есть многочлен наинизшей степени, делящийся на каждый из данных. См. также Наибольший общий делитель. НАИМЕНЬШЕЙ КРИВИЗНЫ ПРИНЦИП, то же, что Герца принцип. НАИМЕНЬШИХ КВАДРАТОВ МЕТОД, один из методов ошибок теории для оценки неизвестных величин по результатам измерений, содержащим случайные ошибки. H. к. м. применяется также для приближённого представления заданной функции другими (более простыми) функциями и часто оказывается полезным при наблюдений обработке. H. к. м. предложен К. Гауссом (1794-95) и А. Лежандром (1805-06). Первоначально H. к. м. использовался для обработки результатов астрономич. и геодезич. наблюдений. Строгое матем. обоснование и установление границ содержательной применимости H. к. м. даны А. А. Марковым (старшим) и A. H. Колмогоровым. Ныне H. к. м. представляет собой один из важнейших разделов матем. статистики и широко используется для статистич. выводов в различных областях науки и техники. Сущность обоснования H. к.
м. (по Гауссу) заключается в допущении, что "убыток" от замены
точного (неизвестного) значения физ. величины Случай одного неизвестного.
Пусть для оценки значения неизвестной величины (коэффициент k > 0
можно выбирать произвольно). Величину pi наз. весом, а Сумма S (X) будет
наименьшей, если в качестве X выбрать взвешенное среднее: Оценка Y величины При нек-рых общих
предположениях можно показать, что если количество наблюдений n достаточно
велико, то распределение оценки Y мало отличается от нормального с математич.
ожиданием
[напр., I (1,96) = 0,950; I (2,58) = 0,990; I (3,00) = 0,997]. Если веса измерений (обе оценки лишены
систематич. ошибок). В том практически важном случае, когда ошибки где постоянная Cn-1 выбрана таким образом, чтобы выполнялось условие: In-1 (oo) = 1. При больших n формулу (2) можно заменить формулой (1). Однако применение формулы (1) при небольших n привело бы к грубым ошибкам. Так, напр., согласно (1), значению I = 0,99 соответствует t = 2,58; истинные значения t, определяемые при малых n как решения соответствующих уравнений In-1(t) = 0,99, приведены в таблице:
Пример. Для определения массы нек-рого тела произведено 10 независимых равноточных взвешиваний, давших результаты Yi (в г):
(здесь ni - число
случаев, в к-рых наблюдался вес Yi, причём n = Случаи нескольких
неизвестных (линейные связи). Пусть n результатов измерений Y1,
Y2,..., Yn связаны с т неизвестными величинами x1,
x2,..., xm (т < п) независимыми линейными
отношениями где аij - известные
коэффициенты, а Так как Е Следовательно, искомые
величины xjпредставляют собой решение системы (4), уравнения
к-рой предполагаются совместными. Точные значения измеряемых величин уi
и случайные ошибки Согласно H. к. м., в
качестве оценок для неизвестных xj применяют такие величины xj,
для к-рых сумма квадратов отклонений будет наименьшей (как и в
предыдущем случае, не могут, вообще говоря, все
обратиться в нуль, и в этом случае S = Сумма квадратов S
представляет собой квадратичный многочлен относительно переменных Xj;
этот многочлен достигает минимума при таких значениях X1, X2,...,
Xm, при которых обращаются в нуль все первые частные
производные: Отсюда следует, что оценки Xj,
полученные согласно H. к. м., должны удовлетворять системе т. н. нормальных
уравнений, к-рая в обозначениях, предложенных Гауссом, имеет вид: Оценки Xj, получающиеся
в результате решения системы нормальных уравнений, лишены систематич. ошибок (EXj
= xj); дисперсии DXj величин Xjравны
kdjj/d, где d - определитель системы (5), а djj
- минор, соответствующий диагональному элементу [
предположениях можно показать,
что если количество наблюдений n достаточно велико, то абс. погрешность
приближённого равенства xj ~ Xj меньше tsj с вероятностью,
близкой к значению интеграла (1). Если случайные ошибки наблюдении не зависят от самих оценок Xj. Один из наиболее типичных случаев применения H. к. м. - "выравнивание" таких результатов наблюдений Yi, для к-рых в уравнениях (3) аij = aj (ti), где aj (t) - известные функции нек-рого параметра t (если t - время, то t1, t2,...- те моменты времени, в к-рые производились наблюдения). Особенно часто встречается в приложениях случай т. н. параболич. интерполяции, когда aj (t)- многочлены [напр., a1 (t) = 1, a2 (t) = t, а3 (t) = t2, ...и т. д.]; если t2 - t1 = t3 - t2 =...= tn - tn-1, a наблюдения равноточные, то для вычисления оценок Xj можно воспользоваться таблицами ортогональных многочленов, имеющимися во многих руководствах по современной вычислительной математике. Другой важный для приложения случай - т. н. гармонич. интерполяция, когда в качестве aj(t) выбирают триго-нометрич. функции [напр., aj (t)= cos(j-1)t,j = 1,2,..., т]. Пример. Для оценки точности одного из методов хим. анализа этим методом определялась концентрация CaO в десяти эталонных пробах заранее известного состава. Результаты равноточных наблюдений указаны в таблице (i - номер эксперимента, ti - истинная концентрация CaO, Ti - концентрация CaO, определённая в результате химического анализа, Yi = Ti - ti - ошибка химического анализа):
Если результаты хим. анализа
не имеют систематич. ошибок, то ЕYi = О. Если же такие ошибки
имеются, то в первом приближении их можно представить в виде: ЕYi
= Для отыскания оценок Yi = x1 + x2 (ti
- t), ? =
1,2,..., 10, поэтому
ai1 = 1, ai2 = ti - t
(согласно предположению о равноточности наблюдений, все Дисперсии компонент решения
этой системы суть где k - неизвестная
дисперсия на единицу веса (в данном случае k - дисперсия любой из
величин Yi). T. к. в этом примере компоненты решения
принимают значения X1 = - 0,35 и X2 = - 0,00524, то
Если случайные ошибки
наблюдений подчиняются нормальному распределению, то отношения |Xj
- xj|sj (j = 1,2) распределены по закону Стьюдента. В
частности, если результаты наблюдений лишены систематич. ошибок, Во многих практически важных случаях (и в частности, при оценке сложных нелинейных связей) количество неизвестных параметров бывает весьма большим и поэтому реализация H. к. м. оказывается эффективной лишь при использовании современной вычислительной техники. Лит.: Марков А. А., Исчисление вероятностей, 4 изд., M., 1924; Колмогоров A. H., К обоснованию метода наименьших квадратов, "Успехи математических наук", 1946, т. 1, в. 1; Л и н н и к Ю. В., Метод наименьших квадратов и основы математико-статистической теории обработки наблюдений, 2 изд., M., 1962; Helmert F. R., Die Ausgleichungsrechnung nach der Methode der kleinsten Quadrate..., 2 Aufl., Lpz., 1907. Л. H. Большев. |
|
© (составление) libelli.ru 2003-2020 |